[📌 namdarine’s AI Review] Language Models are Few-Shot Learners
GPT-3 Paper Breakdown: How Few-Shot Learning Transformed NLP
If you have ever used ChatGPT, Gemini, or Claude, you have already experienced the results of this paper. “Language Models are Few-Shot Learners,” published by OpenAI in 2020, is the foundational work that defined how today’s conversational AI operates. It holds the answer to why AI can tackle new tasks after being shown just a handful of examples.
This paper begins with a single question: “Can large language models learn from context alone, without fine-tuning?”
Language Models are Few-Shot Learners, published in 2020, is the paper that experimentally demonstrated the potential of few-shot learning and in-context learning through GPT-3.
This research moves beyond the prevailing NLP paradigm of Pretrain Fine-tune and proposes the hypothesis that “if a model is made large enough, it can learn from examples provided in context alone—without any weight updates.”
Paper Summary
When model scale is pushed to the extreme, a language model naturally acquires the ability to learn from in-context examples alone—without any weight updates. This capability is known as few-shot learning.
The Real Question This Paper Asks
GPT-1 established the strategy of pre-training followed by fine-tuning. The next logical question was obvious:
“Could it work without fine-tuning at all?” This paper is an experiment to explore exactly that possibility.
TL;DR
- Traditional NLP required fine-tuning plus large labeled datasets for every individual task.
- GPT-3 tests a hypothesis: “If a model is made large enough, it can learn from in-context examples alone, without any weight updates.”
- This hypothesis was tested using a model with 175 billion parameters.
- As model scale increases, validation loss decreases following a power law.
- In particular, few-shot performance improved dramatically.
- Conclusion: A large language model internally acquires the ability to “learn how to learn.” It can perform new tasks without fine-tuning.
The Limits of Traditional NLP: Three Problems with the Fine-Tuning Paradigm
The standard workflow was as follows:
- Large-scale corpus pre-training
- Task-specific fine-tuning
This structure had three major problems:
- Data requirements. Thousands to tens of thousands of labeled examples were needed for any specific task.
- Questionable generalization. Fine-tuned models perform well within the narrow distribution of their training data, but generalize poorly beyond it and risk learning spurious correlations in the data.
- The gap with human ability. Humans can perform new language tasks from just a few examples or a brief natural-language description. Traditional systems struggled enormously to replicate this.
Meta-Learning and In-Context Learning
The authors propose meta-learning as an alternative to overcome these limitations.
Meta-learning means the model develops broad skills and pattern-recognition abilities during pre-training, then leverages them at inference time to rapidly adapt to new tasks.
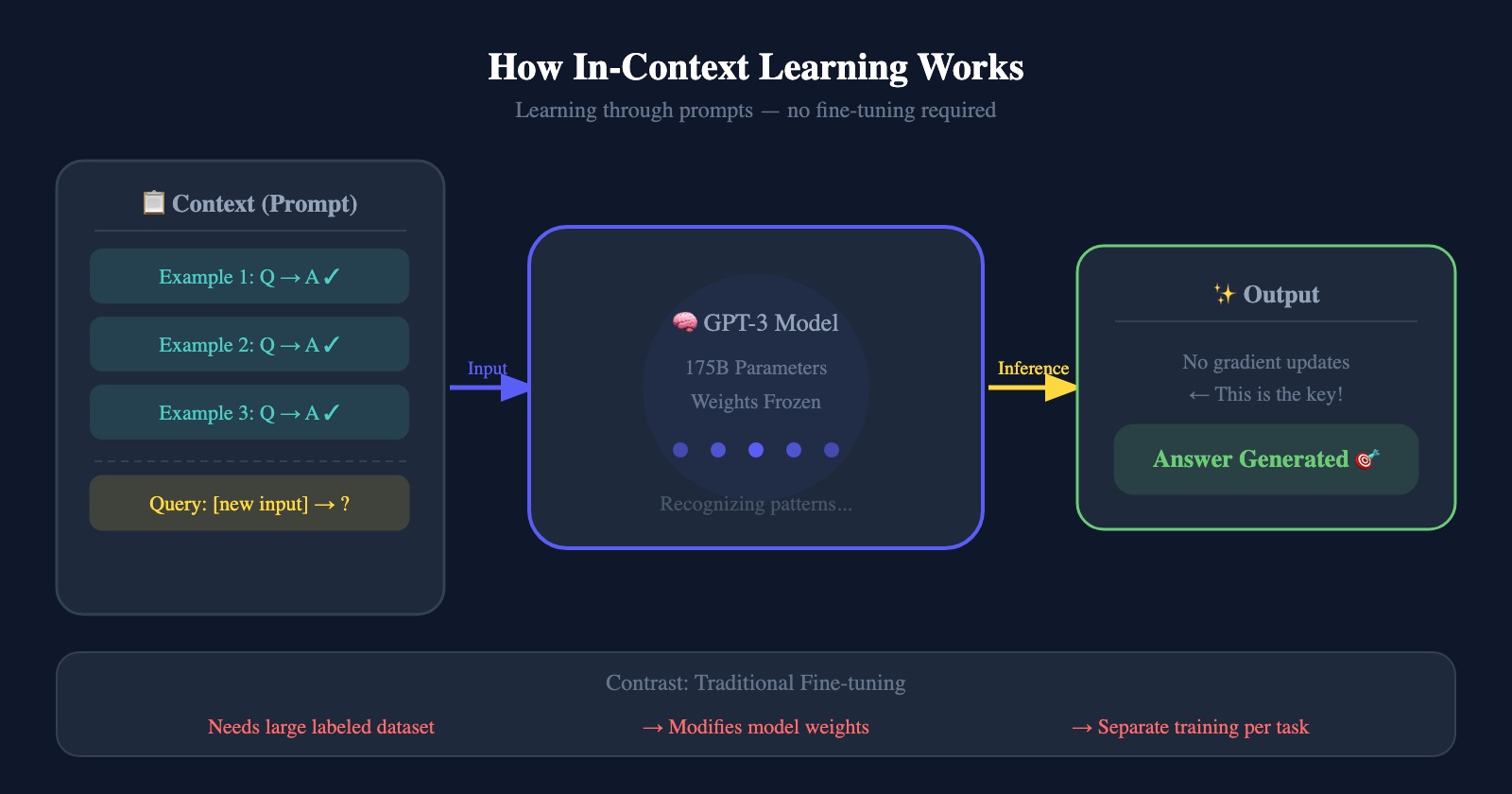
In-context learning corresponds to the inner loop of meta-learning: a pre-trained model is given a natural-language instruction or a few examples as a prompt, and it performs the task without any gradient updates to its weights.
As the authors themselves acknowledged, however, this paper does not fully explain why in-context learning works. Whether the model is truly “learning” from the in-context examples or simply “retrieving” capabilities acquired during pre-training became a central debate in subsequent research.
Economies of Scale: The Hypothesis Behind Scaling Up
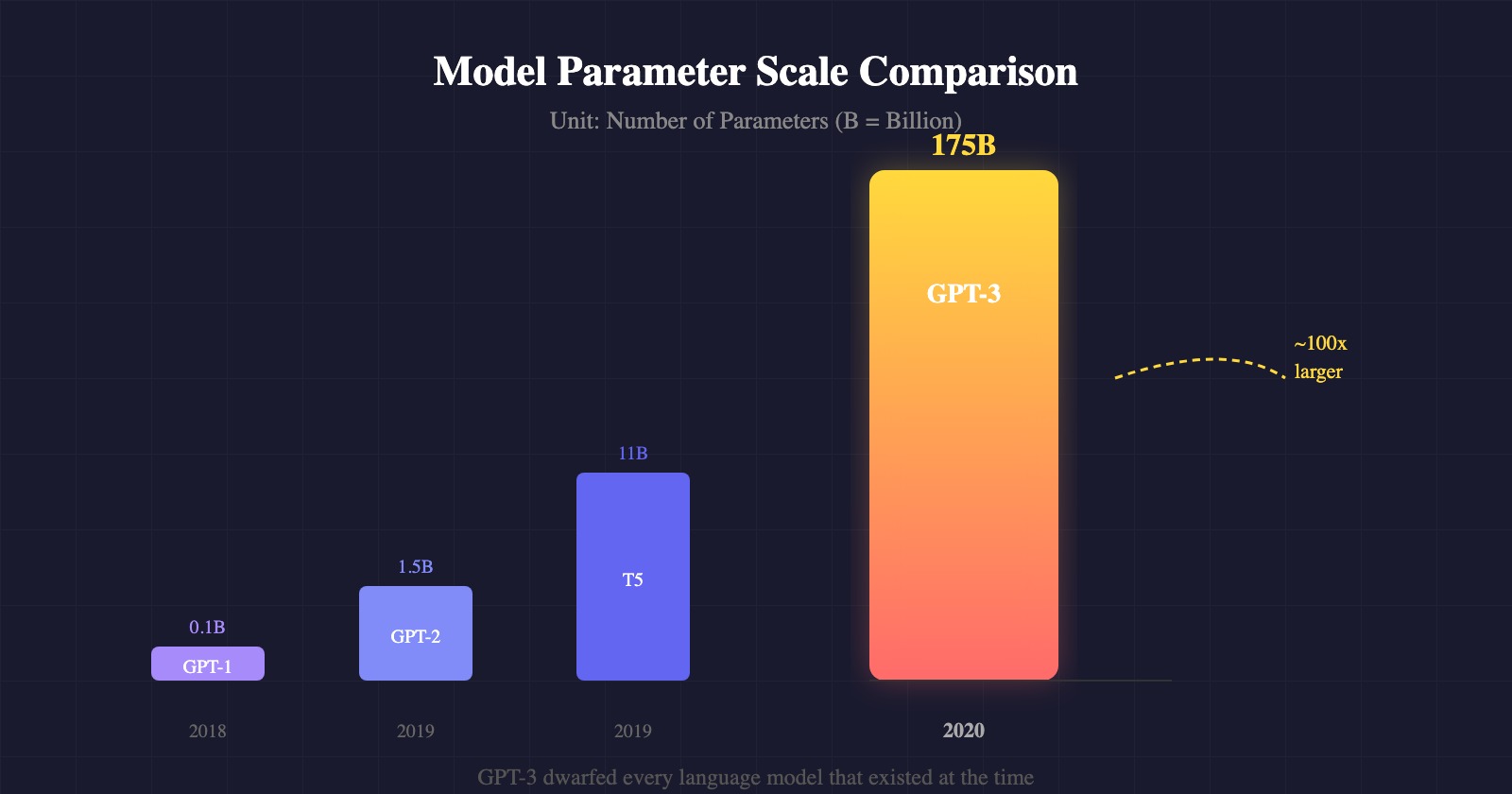
The central hypothesis of this paper is that “scaling up the parameter count of a language model will dramatically improve its in-context learning ability.” The authors trained GPT-3 with 175 billion parameters—far beyond GPT-2’s roughly 1.5 billion—making it more than ten times larger than Microsoft’s Turing-NLG (17B), the largest non-sparse language model at the time.
The authors aimed to confirm that as the model scale grows, so does the model’s ability to use in-context information more efficiently to learn new tasks.
Evaluation Conditions
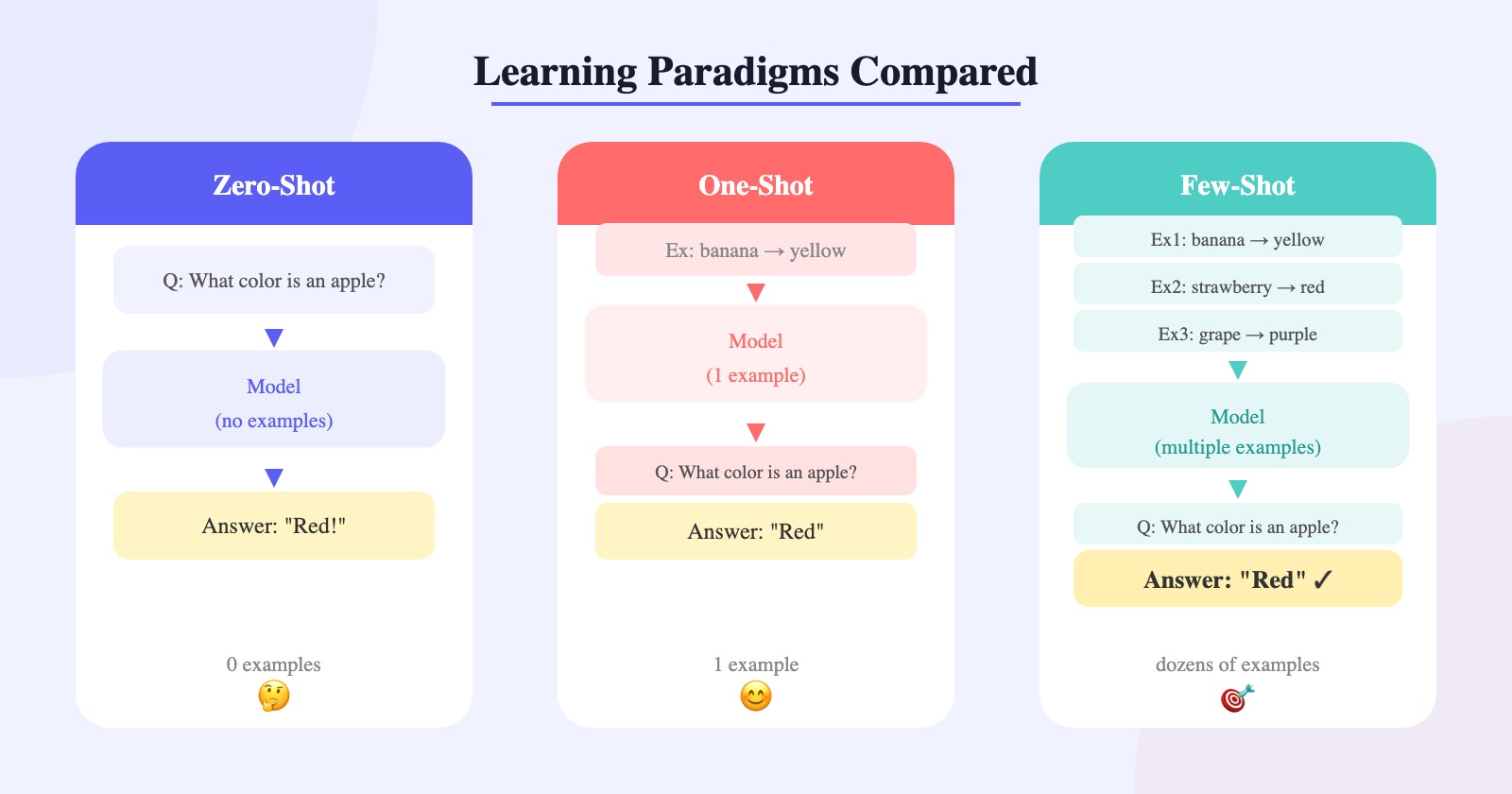
To measure GPT-3’s performance, the authors defined four scenarios:
- Zero-Shot (0S): Only a natural-language description of the task is provided. The most robust and convenient setup, but also the most challenging—without any examples, the model may struggle to understand the expected output format.
- One-Shot (1S): One demonstration example is provided alongside the description. This mirrors saying to someone, “Here’s how it works–-now you try.”
- Few-Shot (FS): As many examples as fit in the model’s context window (typically 10-100; n_ctx=2048) are provided. There are no weight updates; the model predicts the answer by reading the pattern in the provided examples.
- Fine-Tuning: The traditional approach of directly updating the model’s weights using tens of thousands of labeled examples. Highly effective, but requires a large dataset for every new task and can suffer from poor generalization. This approach was not used in the present study; it was included only as a reference point.
Model Architecture
-
Architecture: Inherits GPT-2’s structure (modified initialization, pre-normalization, etc.) and applies alternating dense and locally banded sparse attention patterns similar to the Sparse Transformer. In plain terms, the model alternates between carefully reading every part of a sequence (dense) and skimming nearby important tokens (sparse)—processing vast amounts of information faster and more efficiently. This accounts for less than 10% of the total compute.
-
Scale: Eight model sizes ranging from 125 million to 175 billion parameters were trained, allowing the authors to track how performance changes with scale.
-
Configuration: All models use a context window of 2,048 tokens. Weight initialization and hyperparameters were chosen with computational efficiency in mind.
Training Dataset
A massive dataset amounting to roughly one trillion words was used:
- Common Crawl: A broad internet crawl dataset. Large in volume but low in quality; filtered by similarity to high-quality documents and deduplicated using fuzzy deduplication`.
- High-quality source augmentation: WebText2, two book corpora (Books1 and Books2), and English Wikipedia were added to diversify the data.
- Sampling strategy: Rather than training on all data in proportion to its size, higher-quality sources were sampled more frequently to guide the model toward better information.
Fuzzy Deduplication
Spark’s MinHashLSH implementation (using 10 hash functions) was employed. This process removed duplicates not only within each dataset but also across datasets, reducing the total dataset size by an average of 10%.
Fuzzy deduplication is analogous to scanning a vast library for near-identical copies of the same book and keeping only one, so the model does not repeatedly study the same material.
Evaluation and Analysis
- Evaluation method: For multiple-choice tasks, the likelihood of each candidate token is compared; for open-ended tasks, answers are generated using beam search.
- Data contamination prevention`: Because the training data was scraped from the internet, test-set questions could inadvertently appear in training data—a problem known as “data contamination.” A dedicated analysis pipeline was used to detect and filter this out.
Imagine a librarian who has read every book ever written—the central figure running through the entire paper.
-
Training data (reading): The librarian voraciously reads everything—general web pages (Common Crawl), encyclopedias (Wikipedia), and novels (Books). Rather than reading passively, the librarian re-reads verified classics (high-quality data) multiple times to develop deep knowledge.
-
Model scale (cognitive capacity): Just as a person with greater working memory can draw more connections when reading, a model with 175 billion parameters understands and links information at a level far beyond one with 125 million. The larger the model, the more readily it answers questions it has never encountered before.
-
Evaluation modes (test formats)
- Fine-tuning: “You’re only sitting the math exam tomorrow, so set everything else aside and memorize the formula sheet.” (Task-specific specialization)
- Few-Shot: “Here are five past exam questions with answers. Now solve question six.” (Pattern recognition)
- One-Shot: “Take a look at this one worked example and solve the next problem.” (Core understanding)
- Zero-Shot: “Just solve this problem. All the instructions are in the question.” (Pure intelligence test)
Ultimately, the authors are asking: “If our librarian (GPT-3) has read enough books and has a large enough brain, can it pass a SAT using only the worked examples printed in the margin of the test booklet (in-context learning)—without ever attending a prep course (fine-tuning)?”
Data Contamination Analysis and Handling
- Detection method: All test and development datasets were searched for 13-gram (13 consecutive word) overlaps with the training data.
- Analysis process: Overlapping instances were classified as “dirty,” and a separate “clean” version of each benchmark was created with those instances removed.
- Performance comparison: Results on the clean dataset were compared with results on the full dataset. The performance difference was negligible for most benchmarks; results that were judged to be severely contaminated were either excluded from the report or flagged with and an asterisk (*) to preserve credibility.
The authors essentially checked whether any exam questions had leaked into the students’ study materials before the test. If they had, those questions were excluded from grading, and performance was re-evaluated on the remaining items alone—ensuring a fair assessment.
These analysis steps are crucial evidence that GPT-3’s impressive performance reflects genuine language understanding rather than mere memorization of training data.
GPT-3 Performance Analysis: When Few-Shot Surpasses Fine-Tuning
Economies of Scale (Scaling Laws)
-
Validation results: As the number of parameters and the amount of compute increased, validation loss decreased following a power law. Specifically, multiplying compute by 10 consistently reduced loss by approximately . This predictable relationship later served as empirical grounding for Scaling Law research.
-
Emergence of meta-learning: As model size grew, few-shot performance rose far more steeply than zero-shot or one-shot performance. In other words, larger models are dramatically better at reading in-context examples and adapting on the fly.
Performance Summary by Task
-
Language modeling and text completion: On the LAMBADA dataset, few-shot performance set a new state-of-the-art by a margin of 18 percentage points, demonstrating strong long-range context comprehension.
-
Closed-book question answering: The model’s ability to answer questions using only knowledge stored in its parameters—without retrieving external information—was tested. In the few-shot setting on TriviaQA, GPT-3 achieved 71.2%, outperforming fine-tuned models.
-
Translation: Despite being primarily an English model, GPT-3 demonstrated translation ability drawn from the small amount of multilingual data included in its training (beyond English Wikipedia), with particular strength in translating into English.
-
SAT analogies: GPT-3 achieved 65.2% accuracy on SAT-style word analogy questions, surpassing the average human test-taker score of 57%.
-
Synthesis and generative tasks (GPT-3’s showcase):
- Arithmetic: Three-digit addition and subtraction were performed with high accuracy, suggesting the model had internalized arithmetic rules rather than simply memorizing answers.
- News article generation: Human evaluators could distinguish articles written by the 175-billion-parameter model from real news articles only 52% of the time—essentially a coin flip. By contrast, articles generated by the smallest model (125M parameters) were identified as machine-written 76% of the time, showing that human detection ability drops sharply as model size grows.
GPT-3’s Weaknesses
GPT-3 showed weaknesses in natural language inference (NLI) and certain reading comprehension tasks. On benchmarks such as ANLI, QuAC, and WIC (word-in-context), which require comparing two sentences or disambiguating word meanings, the model continued to lag significantly behind humans and fine-tuned models—even at the largest scale.
The authors attributed these weaknesses to an architectural constraint: GPT-3’s autoregressive (unidirectional) structure processes text strictly left to right, placing it at a disadvantage on tasks that require bidirectional information.
Think of it as the librarian’s report card:
- General knowledge and writing: In subjects that reward broad background knowledge—like essay composition—the librarian outscored students who had drilled a single subject (fine-tuned models). A lifetime of reading pays off.
- Math and logic: On high-level reasoning problems (NLI) and tricky disambiguation tasks (WIC), the librarian stumbled. Reading widely does not automatically translate into mathematical skill.
- The few-shot advantage: The librarian’s real strength is adaptability—glancing at five worked examples in the margin of a test booklet and immediately grasping the required approach. No prep course needed; a handful of past examples is enough.
Why Few-Shot Performance Rises Steeply as Model Scale Increases
Because in-context learning and meta-learning capabilities become dramatically more refined in larger models.
Increased Efficiency in Context Use
As the model scale grows, the efficiency with which the model uses information in the input context improves markedly. Larger models are more sensitive to patterns across the multiple demonstrations provided in a few-shot setting, and their “learning curve”—the performance gain from each additional example—is far steeper than that of smaller models. In short, larger models understand more quickly and accurately “what task they are being asked to do” from the instructions and examples in context.
Proficiency as Meta-Learners
The authors define the process by which a language model develops broad skills and pattern-recognition abilities by reading vast amounts of text during pre-training as ‘meta-learning’. As model capacity increases, this meta-learning ability strengthens: at inference time, even for a task the model has never seen before, a few examples are sufficient for it to instantly identify and deploy the relevant skills from its vast pre-trained knowledge. Indeed, the widening performance gap between zero-shot and few-shot settings as model size grows is evidence that larger models are superior meta-learners.
Knowledge Absorption
Model capacity (parameters) is directly linked to the ‘quantity of knowledge’ the model can absorb during pre-training. A model as large as GPT-3—with 175 billion parameters—learns the subtle and complex linguistic patterns and world knowledge contained in the vast web corpus far more densely than smaller models. Thanks to this richly accumulated internal knowledge, even a small hint (a few examples) in the few-shot stage is enough to trigger and an explosive retrieval of relevant knowledge, dramatically increasing the probability of a correct answer.
In brief, larger models develop the applied intelligence (in-context learning) to identify rules from given examples and reorganize existing knowledge to fit those rules.
Why Unidirectional Architecture Is Disadvantaged on Certain Tasks
The limitation is structural and algorithmic. On tasks such as sentence-pair comparison, a unidirectional model processes text sequentially from left to right and predicts the next token. A bidirectional architecture, by contrast, can attend to the entire sentence at once, learning richer representations. Unidirectional models have advantages in sampling and probability computation, but they fall short of bidirectional models on tasks that require filling in the middle of a sequence or making comparisons that depend on integrating information from both directions.
Overcoming BPE Tokenizer Limitations
GPT-3 can perform character-level manipulation tasks (such as spelling and word manipulation) despite the constraints of BPE tokenization, because in-context learning enables the model to develop sophisticated pattern-matching that understands the internal substructure of tokens.
-
Understanding token substructure: BPE encoding typically processes a significant portion of a word (roughly 0.7 words per token on average) as a single unit, making direct access to individual characters difficult. GPT-3 has learned to “pull apart” tokens and reason about their constituent characters.
-
Rule acquisition through in-context learning: The model is almost unable to perform such manipulations in a zero-shot setting, but performance improves dramatically in the few-shot setting—indicating that new symbolic manipulation rules are learned on the fly from the text patterns presented at inference time.
-
Emergent intelligence with scale: Character-level manipulation ability improves smoothly as model size increases. In particular, GPT-3’s 175 billion parameters give it sufficient capacity to perform complex manipulations and non-trivial computations that smaller models cannot handle at all.
-
Non-deterministic retrieval: Correctl answering these tasks requires the model to conduct internal search and complex computation. Large models effectively exercise this non-tokenization-based pattern-matching skill.
GPT-3 thus overcame the structural constraints of BPE by grasping fine-grained character-level structure and applying logical reasoning on the fly from provided examples.
Other Technical Limitations
Semantic Repetition and Loss of Coherence
-
Document-level repetition: GPT-3’s generated samples tend to unnecessarily repeat sentences or concepts that carry the same meaning when viewed across the full document.
-
Lack of long-range coherence: As text grows longer, the model tends to lose the logic or topic established at the outset, producing contradictions or non-sequiturs.
-
Visible in news article generation: Although GPT-3’s output is difficult to distinguish from human writing at a glance, these repetitions and unnatural phrases, when examined closely, serve as telltale signs of machine-generated text.
These issues stem from the limitations of the unidirectional architecture, the flat pre-training objective`, and the absence of grounding in real-world knowledge“.
*Flat pre-training objective: All tokens are weighted equally, so the model cannot distinguish keywords from function words.
** Absence of real-world grounding: The model learns the world purely through textual statistics, with no embodied or perceptual experience.
Sample Inefficiency (Compared to Humans)
GPT-3 processes approximately 300 billion tokens during pre-training—far more text than a human encounters in a lifetime. The root causes are again the flat training objective and the disconnection from real-world knowledge. This demonstrates both the limits of scaling and the need for alternatives: scaling alone cannot solve the efficiency problem. Proposed remedies include learning an abjective from human feedback (RLHF) or grounding the model in the real world by incorporating multiple modalities such as images and video.
Societal Impact
Misuse of Language Models
Because GPT-3 can perform new tasks from just a few examples or instructions—without fine-tuning—its versatility and adaptability are equally powerful tools in the hands of bad actors.
-
Lowered barriers to entry: Producing high-quality misinformation or phishing content previously required significant human resources. GPT-3 enables the large-scale generation of persuasive text at low cost, dramatically lowering the barrier to abuse.
-
Limits of human detection: As the experiments showed, humans distinguished GPT-3-generated news articles from real ones only about 52% of the time. If model-generated content is weaponized for disinformation campaigns or spam, the potential for widespread social disruption is significant.
Fairness, Bias, and Representation
The vast internet data used to train GPT-3 contains not only the breadth of human knowledge but also society’s prejudices and stereotypes.
-
Reflection of internet-scale bias: The model learns and reproduces biases present in its training data. For example, in an occupation-gender association test, 83% of occupations were more strongly linked to male identifiers, and female identifiers co-occurred more frequently with appearance-related words such as “beautiful” and “gorgeous.”
-
Racial and religious bias: The model displayed consistently negative or positive sentiment toward certain racial groups (e.g., lower sentiment scores for “Black”) and associated certain religions more frequently with negative terms such as “violence” and “terrorism.”
-
Correlation with scale: GPT-3 (175B) demonstrated higher accuracy and greater robustness on certain bias benchmarks (e.g., Winogender) compared with smaller models—suggesting that larger models may handle bias more sophisticatedly, while still fundamentally harboring prejudice.
Energy Usage
The large-scale pre-training of massive models consumes enormous amounts of energy.
- Amortization of training cost: Training GPT-3 (175B) required thousands of petaflop/s-days of compute. However, the authors argue that once trained, a large model can be applied to thousands of tasks without retraining (via few-shot), making it more resource-efficient in the long run than building a new model for every task—an amortization effect.
Our librarian has both a bright side and a shadow:
-
Misuse: Given just a few examples, the librarian can produce a convincing love letter or a sophisticated phishing email. Greater ability brings greater risk of misuse.
-
Bias: Many of the books the librarian read contained prejudice. Without realizing it, the librarian may make discriminatory remarks about certain groups—because the biases of the internet were absorbed wholesale during training.
-
Energy: Raising this librarian costs enormous resources (electricity). But once fully trained, the librarian can be assigned thousands of different tasks without additional schooling—making the investment efficient over the long haul.
In conclusion, the paper emphasizes that for GPT-3’s revolutionary capabilities to benefit humanity, ongoing research into abuse prevention and bias mitigation must go hand in hand with further development.
The Significance of GPT-3: The Dawn of the In-Context Learning Era
This paper did not propose a new architecture. Instead, it opened up a possibility: “You can learn without fine-tuning.” This single sentence became the starting point for prompt engineering, in-context learning research, and the scaling journey that led to GPT-4, GPT-5 and beyond.
The Starting Point of “AI That Learns from Examples”
This paper is not merely an experiment in building a bigger model. It was the first work to challenge the assumption that “learning must occur through weight updates.” Language Models are Few-Shot Learners moved beyond the fine-tuning-centric NLP paradigm and pointed toward a new direction: models that adapt through context.
GPT-3 was not perfect. It showed weaknesses in logical reasoning and revealed issues of bias and misuse. And yet, the paper left behind one undeniable fact:
A sufficiently large model can learn from examples alone. The librarian who has read every book in the world is now ready to sit an exam without attending a single prep course. What that librarian has learned—and what biases it harbors—is something we must continue to examine.
It is upon this question that GPT-4, GPT-5, and today’s entire LLM ecosystem have been built.
📌 namdarine’s AI Review is a series that breaks down papers, algorithms, and architectures so anyone can understand the core ideas behind AI.
Let’s build it like it’s already happened.
→ See you in the next review!