[📌 namdarine’s AI Review] What BERT Changed Wasn't the Architecture — It Was the Direction of Reading
In 2018, Google published a paper. Within months, NLP benchmark leaderboards were overturned. A year after that, nearly every NLP paper was citing it. That paper was BERT (Bidirectional Encoder Representations from Transformers). Its approach seemed to offer a path toward more accurate language understanding — and even hinted at reducing issues like hallucination. But due to structural constraints, eight years after its release, BERT has become the standard not in generative AI, but in a different domain entirely. Today, I want to talk about BERT — a model that looked poised to fix GPT’s weaknesses, but ended up carving out a different place for itself.
BERT’s real contribution is not its performance numbers. The state-of-the-art results across eleven NLP tasks are consequences, not the cause. What made those results possible was an answer to a far more fundamental question: “Does the direction in which a language model reads text determine the quality of its representations?” BERT answered yes — and simultaneously found a way to remove that constraint. In doing so, it collapsed the fragmented landscape of NLP into a single converging paradigm: one pre-trained model, universally applicable. What this paper changed was not a model’s performance, but how an entire field defines its problems.
The 2018 Wall: Why Bidirectionality Was Impossible
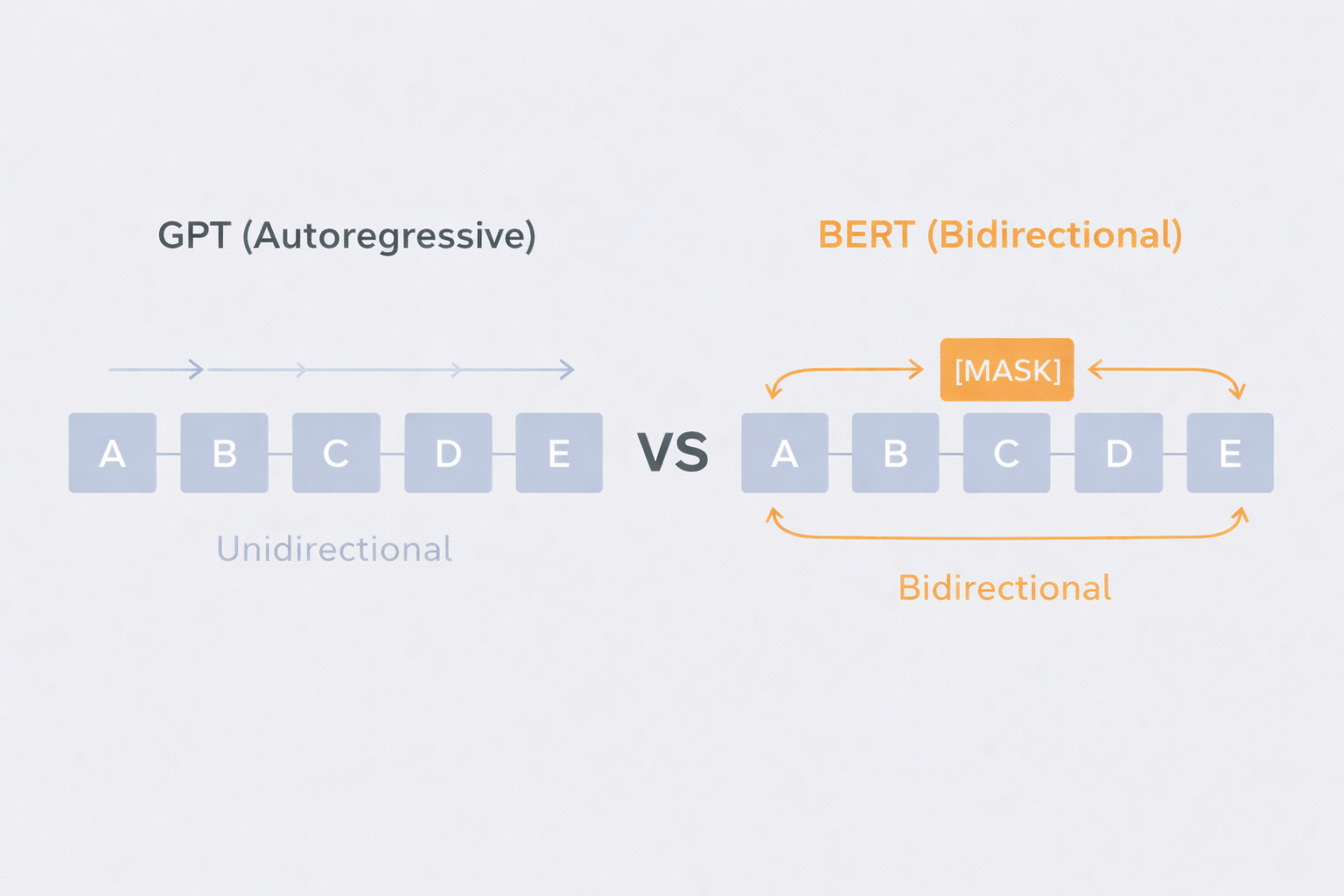
Before 2018, there was one structurally unresolved constraint in language representation learning. All language models were unidirectional. This might appear to be a design choice, but it had an unavoidable mathematical basis. Standard autoregressive language models compute conditional probabilities sequentially, left-to-right or right-to-left. If you condition bidirectionally and simultaneously, the model already “sees” the token it is supposed to predict, and trivially learns to copy it rather than infer it from context. Bidirectionality and autoregressive training were theoretically incompatible.
ELMo worked around this problem. It trained a left-to-right LSTM and a right-to-left LSTM independently, then shallowly concatenated their outputs. On the surface, this looked bidirectional, but internally it was not. Each directional representation was formed without any awareness of the other direction’s context. When encoding the word “bank,” the left-to-right LSTM sees only what precedes it, and the right-to-left LSTM sees only what follows. Concatenating these two representations after the fact is fundamentally different from integrating both contexts simultaneously at every layer. OpenAI GPT abandoned the problem entirely, using only a left-to-right Transformer. As a result, no token could attend to anything on its right, a structural limitation that proved particularly damaging for token-level tasks like question answering and named entity recognition, where resolving a word’s meaning often depends critically on what comes after it.
Think of it this way. Two detectives are assigned to the same case. One investigates only the first half of the events; the other investigates only the second half. When the investigation is over, their reports are stapled together. That is ELMo. BERT, by contrast, has both detectives sitting in the same room from the start, looking at all the evidence together and working through it in real time. The depth of the result is fundamentally different.
In short, NLP in 2018 was trapped in a state of “wanting to read bidirectionally, but being unable to.”
BERT’s Solution: Masking as a Workaround
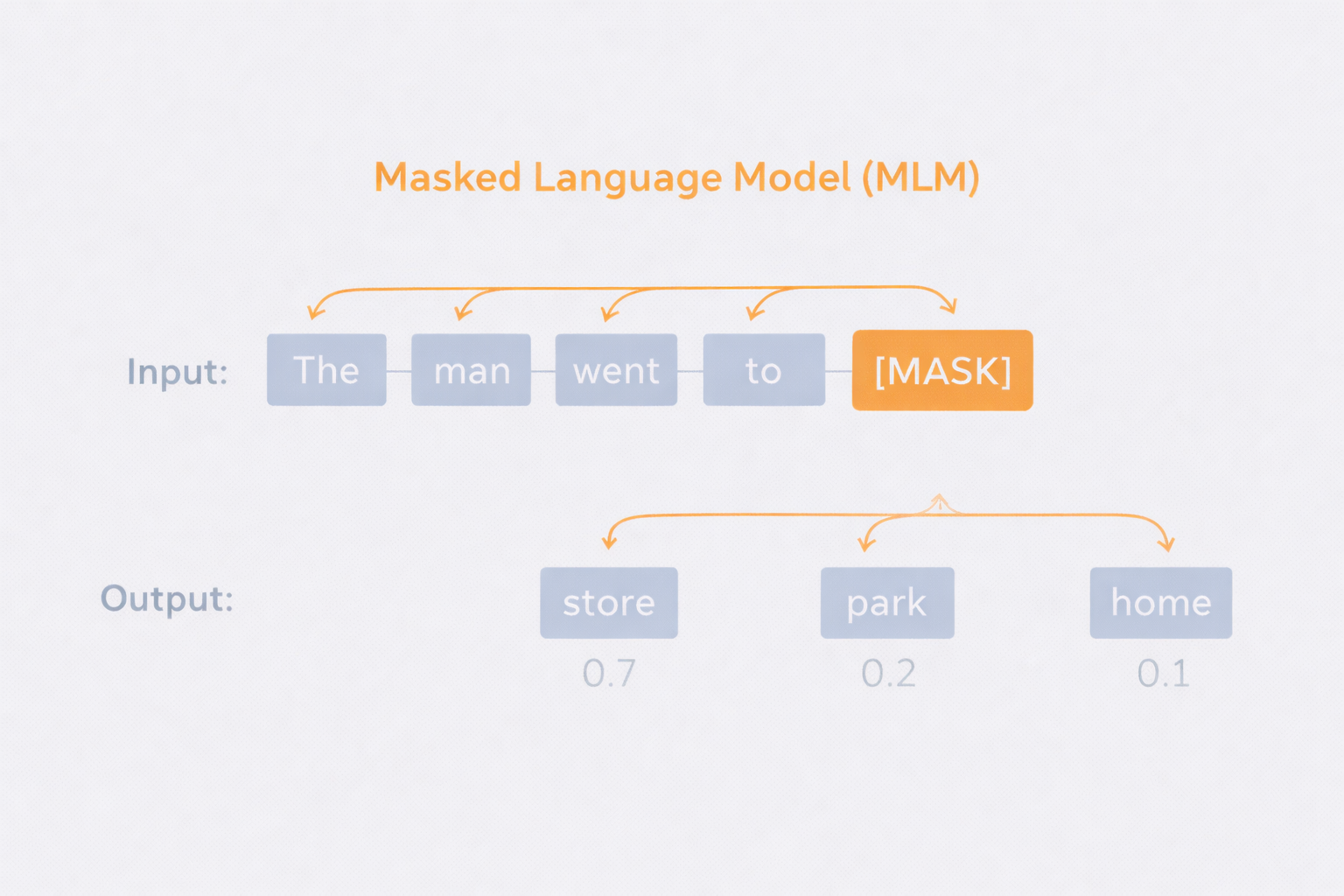
BERT’s core mechanism is the Masked Language Model, or MLM. But understanding it as simply “masking 15% of tokens” misses the point. What MLM actually solves is the information leakage problem that makes bidirectional training intractable. By removing the target token from the input, the model is forced to reconstruct its meaning from both surrounding contexts without the token being present. In this process, every layer of the Transformer attends to both left and right context simultaneously when building representations. This is what separates it structurally from ELMo’s shallow concatenation.
However, this introduces a new problem. The [MASK] token appears only during pre-training and never during fine-tuning, creating a distributional mismatch between the two stages. To mitigate this, BERT uses a deliberate mixed masking strategy. Of the 15%of tokens selected for prediction, 80% are replaced with [MASK], 10% are replaced with a random token, and 10% are left unchanged. The effect of this is subtle but important. Because the model cannot know which tokens have been masked, randomly replaced, or left intact, it is forced to maintain contextually consistent representations for every token in the sequence. This prevents the model from developing shortcuts tied to specific input patterns.
The second pre-training task, NextSentence Prediction, is designed to capture inter-sentence relationships. Conceptually it is reasonable, but subsequent work — most notably RoBERTa — demonstrated that NSP’s actual contribution is limited. Even BERT’s own ablation studies show meaningful degradation on only a subset of tasks when NSP is removed, which suggests the task is not as foundational as the paper implies.
The fine-tuning architecture is equally important to understand. BERT uses the same architecture for both pre-training and fine-tuning, with the [CLS] token serving as an aggregate representation for classification tasks and [SEP] marking sequence boundaries. This unified design allows classification, sequence tagging, question answering, and textual entailment to be handled with minimal task-specific parameters added on top.
The core idea is simple: cover the answer and force the model to reason from both sides. That is all BERT does — and that is everything.
Paradigm Reversal: The Model Becomes the Center
In the pre-BERT paradigm, designing task-specific architectures was standard practice. BiDAF was built for question answering. ESIM was built for natural language inference. Pre-trained representations played a supporting role, injected as additional features into these hand-engineered systems. ELMo exemplified this approach.
BERT inverted that relationship. The general-purpose pre-trained model becomes the center, and task-specific components become thin additions at the top. The significance of this inversion goes beyond convenience. Because all parameters are updated jointly during fine-tuning, the rich representations formed during pre-training are precisely adjusted by task-specific signals. In the feature-based approach, pre-trained representations are frozen, meaning the downstream task cannot modify the representations themselves.
The comparison with GPT reveals how surgically this paper was designed. BERT-base was intentionally built to match GPT’s model size, so that the only meaningful variable between the two would be the directionality of attention. At equivalent scale, this difference alone accounts for roughly 4.5 percentage points in average GLUE accuracy — a remarkable clean isolation of bidirectionality’s contribution.
The findings on model scale are also structurally significant. It was already known that larger models help on large-scale tasks, but BERT demonstrated that scale benefits persist even on tasks with only a few thousand labeled examples. This implies that when pre-training is sufficiently deep and broad, a larger representational capacity can be effectively leveraged through even minimal fine-tuning data.
After BERT, the question shifted from “which model should we use?” to “how should we train it?”
What BERT Gave Up
The most fundamental limitation of BERT stems directly from MLM itself. Because only 15% of tokens are predicted per batch, the model receives far fewer learning signals per unit of computation than an autoregressive model that predicts every token. This means BERT requires substantially more pre-training steps to converge — a cost the paper itself acknowledges.
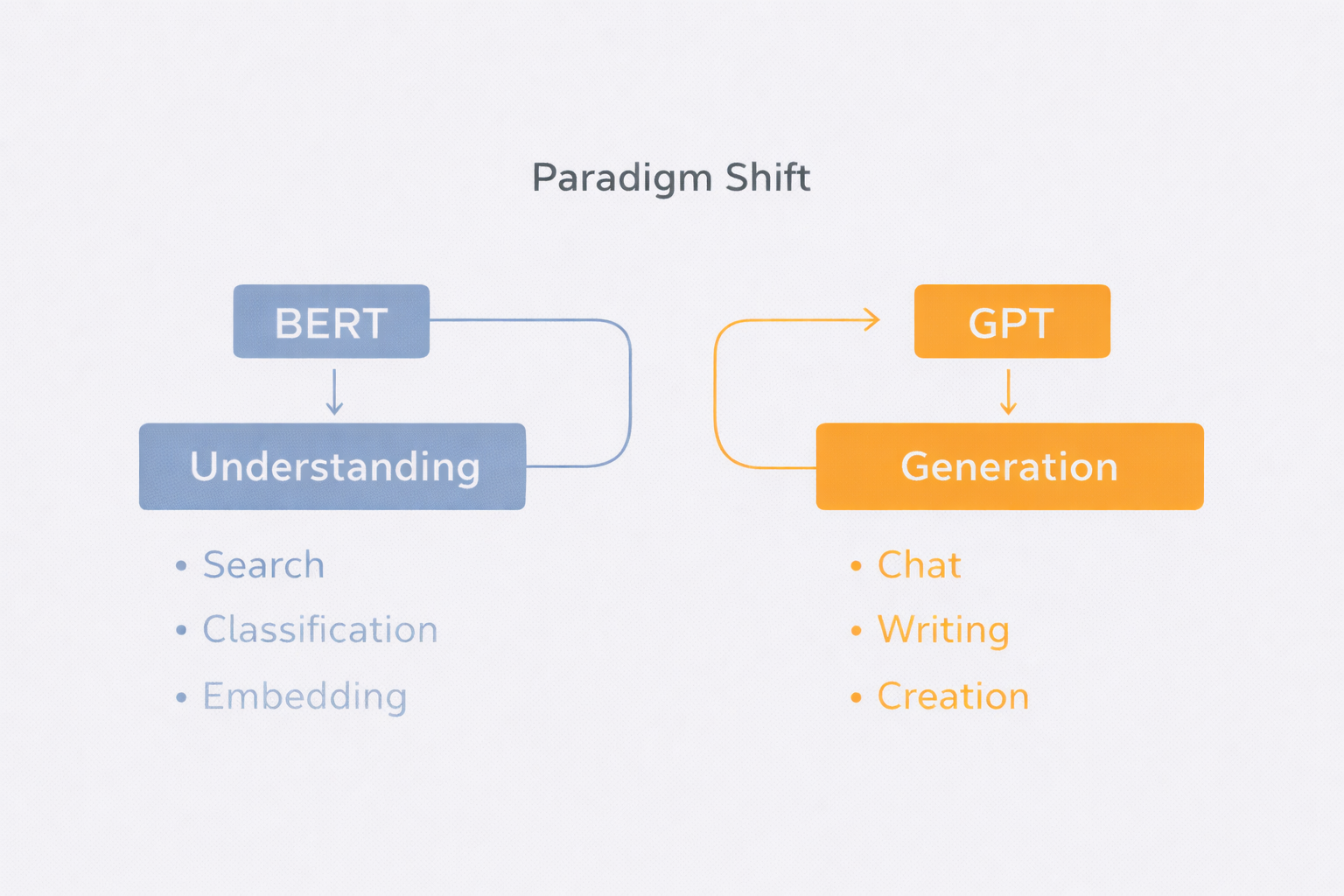
A more consequential limitation is BERT’s structural unsuitability for generative tasks. As an encoder-only model trained to predict masked tokens, it cannot perform autoregressive sequence generation. Tasks like summarization, translation, and open-ended dialogue generation are architecturally inaccessible to BERT without significant modification. This is precisely why the GPT line of models came to dominate generative NLP.
BERT is an exceptional reading teacher, not a writer. It excels at reading text, filling in blanks, and identifying the main point — but it was never trained to write from a blank page, sentence by sentence. This is precisely why conversational AI systems like ChatGPT and Claude emerged from the GPT lineage, not from BERT.
The value of NSP also warrants scrutiny. While the paper claims NSP benefits QA and NLI, RoBERTa surpasses BERT on these same tasks using longer training and larger batches alone, without NSP. This raises the possibility that some of the observed gains attributed to NSP were simply an artifact of exposure to more sentence-pair data, rather than the task itself providing a meaningful inductive bias.
The 512-token context limit is a direct consequence of attention’s quadratic computational complexity. For long documents, legal texts, or code files where long-range dependencies matter, BERT is structurally constrained. This limitation became the driving motivation behind Longformer, BigBird, and a broader line of work on sparse attention mechanisms.
Finally, the pre-training-fine-tuning distributional mismatch is not fully resolved. The [MASK] token never appears during fine-tuning, meaning representations learned in response to masked inputs may not transfer cleanly to unmasked inference contexts. The mixed masking strategy reduces this gap, but the underlying asymmetry remains.
BERT gained “understanding” at the cost of “generation.” The price of that choice only became clear eight years later.
What BERT Left Behind
What BERT opened up was not merely a performance improvement on a single model — it restructured how NLP research itself is organized. Before BERT, each task required a purpose-built architecture. After BERT, the central question became “what to pre-train on and how to fine-tune,” and task-specific architecture design was pushed to the margins.
This was made possible by BERT’s simultaneous achievement of generality and depth. Its representations are rich enough to handle both sentence-level semantic reasoning and fine-grained token-level prediction within the same parameter space. This became the conceptual foundation for multitask learning, prompt-based learning, and ultimately the few-shot learning paradigm that GPT-3 represents. Without BERT establishing so convincingly that a single model can handle diverse language tasks, the proposition that scale alone could generalize across tasks would have been far harder to make credible.
8 Years Later: Where Is BERT Now?
This piece is written in 2026 — eight years after the BERT paper was published. Readers back then didn’t know where BERT was headed. We do now. We know what became the standard, what faded away, and which architectures survived. Reading with knowledge of the outcome is like reading a mystery novel where you can already see the foreshadowing.
What People Expected at the Time
In 2018, many researchers judged BERT to be structurally superior to GPT. Bidirectional context integration seemed like an obvious advantage. The prevailing view was that GPT — reading only left to right — had an inherent limitation that BERT had overcome, so future progress would come from BERT’s direction. That expectation turned out to be wrong.
Why It’s Hard to Call a Winner
Did BERT lose to GPT? It’s hard to say definitively — it’s not even clear the two were competing in the same race. GPT chose generation. BERT chose understanding. And what users wanted was generation. ChatGPT changed the world not because of technical superiority, but because people wanted to have conversations with AI. BERT was never built for that. Google must have known this. When Google — the very company that published BERT — built its own conversational AI (Bard, later Gemini), it chose a decoder-based architecture, not BERT. Even if Google had tried building a chatbot on BERT, the structural disadvantage would have led to the same conclusion eventually.
Pushed Out of the Mainstream, But Found Its Place
As of 2026, BERT is not at the center of conversational AI. ChatGPT, Gemini, and Claude are all decoder-based. In that sense, BERT has been pushed out of the mainstream. But being pushed out is not the same as failing. In semantic search, document classification, and embedding generation, the BERT family remains the industry standard. It can’t hold a sparkling conversation, but it quietly does what it was built to do. It didn’t fail to become a general-purpose AI — it simply found the domain where it performs best. Looking back, BERT never tried to be a generative AI to begin with. Google built BERT to improve search quality, and that goal was achieved. Saying “BERT lost to GPT” is grading BERT against a target it never had.
Even as the Architecture Changes
The core ideas BERT proved — bidirectional context integration, the depth of pre-training, the universality of a single model — are present in GPT-4, in Claude, in Gemini. The architecture has changed, but the questions BERT raised are still valid. BERT gave up the starring role. But the stage the stars are standing on is one that BERT built. Some papers are still worth reading eight years later. BERT is one of them.
Some technologies dominate. Others permeate. BERT was the latter.